�l���r�g��2022-03-18���ٷ��Ӌ��C�QՓ���g�[��1��
ժ Ҫ�� ժ Ҫ����ȌW����Ŀǰ�C��ҕ�X��ǰ�ؽ�Q���������������|����Ӗ������������ȌW����Q�C��ҕ�X���}�Ļ������ϡ��ռ��͜ʴ_��ע�D������һ���O���M�r�Ҵ��r���F���^�̡��S���C��ҕ�X�ďV�����ã��@�����}����Խ��Խͻ�����D�����V���g��һ�N��Ч��Q��ȌW������
����ժ Ҫ����ȌW����Ŀǰ�C��ҕ�X��ǰ�ؽ�Q���������������|����Ӗ������������ȌW����Q�C��ҕ�X���}�Ļ������ϡ��ռ��͜ʴ_��ע�D������һ���O���M�r�Ҵ��r���F���^�̡��S���C��ҕ�X�ďV�����ã��@�����}����Խ��Խͻ�����D�����V���g��һ�N��Ч��Q��ȌW�����������ߵ��|��Ӗ���������M��Ӗ����һ�N���g�ֶΣ�ԓ���g����ذ��S����ȌW���c�C��ҕ�X�İlչ��ϵ�y��������ǰ�D�����V���g�о��������V�������V���g���˺�̎�������V�������ɵĽǶȣ������F�ЈD�����V���g���о���ʽ�������о���ʽ����F�ЈD�����V���g�ķ��ϵ�y�����c��BÿD�����V�о��Ĵ������о��ɹ�������F�ЈD�����V�о��M�п��Y��ָ����ǰ�D�����V�о��д��ڵĆ��}��δ���İlչڅ�ݡ�
�����P�I�~����ȌW��;Ӌ��Cҕ�X;�D�����V;�������V;�D������
�����C��ҕ�X�еĈD��̎�����˹�������һ����Ҫ���о��I�����D�����Z�x�ָ����ָ��Ŀ�˙z�y�ȑ���[1-3] ���F�A�Σ��S��Ӳ���Oʩ�IJ������ƺ���ȌW��[4] ���g������Լ�����lչ��������ȌW���ĈD������Ҳ�����®����� Alex�ȌW�ߌ���Ⱦ��e�W�j AlexNet[5] �����ڈD�����в�ȡ���h���������y�D���������͵��e�`�ʺ�����ȌW���ĈD��̎����Q�����ɞ��������S���µ���ȌW���W�j�Y������ NiN[6] ��VGG[7] ��ReNet[8] ��GoogLeNet[9] �� ResNet[10] ��InceptionNet[11- 12] ��MobileNet[13- 15] ��DenseNet[16] �� EfficientNet[17] ��ResNeXt[18] �� ResNeSt[19] �ȾW�j�Y���������������ڲ�ͬ�ĈD���È�����Ů��ʡ�
������ȌW����Ӌ��Cҕ�X�I��ȡ�õľ�ɹ�����Ҫ�w������������[1,20-21] ��(1)�������ȌW��ģ�͵ı��_����;(2)��������Ŀɫ@������;(3)��Ҏģ�ɫ@�õĘ�ע�����������˴��M��ȌW���ڲ�ͬ�ĈD��̎���I��İlչ�������fӋ�IJ�ͬ��͵ĈD�����ռ�����ע���_���ã��������������� ImageNet[22] �����ՈD���È����͈D������M�Є��֣��F�Д��������ԏĈD�������Ϸֳ� 2D ��������2.5D �������� 3D������[22-40] �����w�ˈD�����Z�x�и����ָ���Ԅ��{�ȸ������ã��O��ش��M����ȌW���D���g�İlչ���M����ˣ����ڸ��N���I�I�����ȌW���D���ã�ȱ�ٺϸ���I��D����Ȼ��һ���������������������t���D��̎��[41-42] ��AI �r�I[43-44] ���I��
����He�ȌW��[45] ָ���� 2012�� AlexNet[5] �״�ʹ������W�j�M�ЈD�����@�ñ��������y�D��̎���������õ�Ч���ԁ���NASNet-A[46] �������ImageNet�� Top-1 ��ʴ_���ѽ��� 62.5%������ 82.7%��ͬ�r����Ҳָ���@Щ�ɾ͵�ȡ�ã����H�H�w���ھW�jģ�͵��OӋ�̓����������D�����V�ڃȵĶ�N����������Ӗ������Ҳͬ�ӷdz���Ҫ��
�����D�����V������ЧӖ������������r�½�Q��ȌW��ģ��Ӗ�����}��һ�N��Ч���������������V���g�ͷ�����������S�������VӖ���������������W�j�ķ�����������Ҋ�ĈD�����V������Ҫ���ڈD��׃�Q��������׃�������D�����D�����Ӻ�ģ����[1,41,47-48] ���S����ȌW�����W�j�ČӔ������U���_�����IJ��������������܉���÷�ֹģ���^�M�ϣ����F���� mixup[49] ������ĺϳɘӱ��D�����V����[50-57] ��ʹ�����Ɍ����W�j(generative adversarial nets��GANs)[58] �������̓�M�D��ӱ����ɵĈD�����V����[59-63] �ȡ��ڲ�ͬ���Ô������͑��È����£��D�����V�IJ��Ժͷ���Ҳ���M��ͬ����ˣ��������ض��ĈD�����͑��È������ҵ���ѵĈD�����V���ԣ����F�˻����㷨��ģ���M�����V�������������܈D�����V���P�о������磬Fawzi �ȌW��[64] ��������m���D�����V��Cubuk �ȌW��[47] ����˻���ѭ�h�W�j���Ԅ����V��ܡ��������⣬߀�и�����о�[65-71] ��̽�����ܻ����Ԅӻ��ĈD�����V���g��
������ǰ���D�����V���о��ӳ����F�����N�·�������˼·����ر�������������VӖ���D�������ڌӳ����F�ĈD�����V�о��а���ס�D�����V�ķ�ʽ�����F�ЈD�����V�о��M�з��T�e����������о��ˆTᘌ���ͬ��ҕ�X�����ҵ����m�ĈD�����V�����Լ����l�µĈD�����V�о��Ƿdz���Ҫ�ġ�
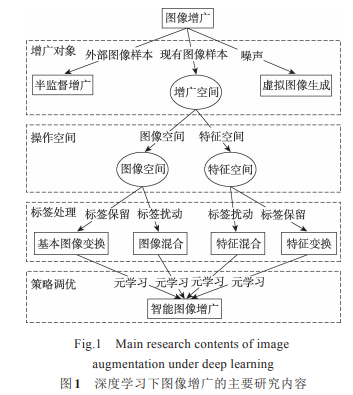
�������ďĈD�����V�Č������Ŀ��g���D��˺���̎����ʽ�͈D�����V���Ե��{����ʽ�Ă��S�ȳ��l���w�{���F�ЈD�����V�о�����Ҫ���ݣ���D 1 ��ʾ��
�������ȣ����ĸ����D�����V�Č���ͬ�ֳ������ⲿ�D��İ�O�����V����������̓�M�D��ӱ���̓�M�D���������V���Լ�����D��Ӗ�������������ĈD�����V����Σ����ď����V�����Ŀ��g�ϣ��^�eֱ���ڈD����g(raw image)�M�����V�Լ��ڈD��ͨ�^ģ���D�Q���[���g(latent space)���V�������D�����V�^�����Ƿ���Ҫ���]�D���ע��Ϣ�Լ����V��a�����ӱ������ӱ������Ę˺��Ƿ���F�_�ӣ������Mһ�����D�����V�ֳɘ˺��������V�͘˺��_�����V������Č�ʹ���㷨����ģ�ʹ_���D�����V�ą������߷������о��w�����܈D�����V�����څ^�e�о��ˆT�ƶ��D�����V�����;��w���ԵĂ��y�D�����V�о���
�������ĵ���Ҫ�о����ݺ�ؕ�I���Կ��Y�飺
����(1)ϵ�y������D�����V�I������P�о�������D�����V���о���ʽ�ͷ���wϵ�������F�����P�о������M�з��
����(2)������������ĈD�����V����wϵ��ÿ��e�еĴ������о��������������о��M�п��^�ķ������ȣ���ָ���@Щ�о��Ą����c���m�È����;����ԡ�
����(3)ӑՓ�����YĿǰ�D�����V�о��I��İlչ�F��о�������δ���İlչ����
�������ĵă������ՈD 2��ʾ�ă����M��չ�_��
����1 �����D�����V
�����������Ȍ������D��׃�Q���V�M�л�������D��׃�Q���V����Ҫ����������Ӗ���������ĈD��ӱ������ض��ĈD��׃�Q����(�����׃�Q������׃�Q��)���a���µĈD��ӱ��Ę˺���Ϣ�cԭʼ�D��ӱ��Ę˺���Ϣ����һ�¡�����ͨ�^������ʽ�����������x�����D��׃�Q���V�ķ�ʽ��
����1.1 ���c�y��׃�Q�D�����V
�����ΈD��׃�Q�ͼy��׃�Q���ڈD��Ďο��g���M�е����V��������Ҫ�����V������� 1���У������D���D������ģ�����s�š��S�C�ü�������׃�Q�ȡ�
����1.1.1 ���D���V
�����D��ķ��D��ָ���� X �S���� Y �S�M�����D��ʹ�� I′ ��ʾ���D��ĈD������ y �S�M�з��D�r��I′ ��ʾ���ҷ��D(Ҳ���īI�Q��ˮƽ�R��)��ĈD��ӱ����� X �S�M�з��D�r��I′ ��ʾ���·��D(��ֱ�R��)��ĈD��ӱ������D�D�����Vʾ����D 3��ʾ�����У���߅�ӈD��ԭʼ�D�����g�ӈD����ԭʼ�D����ͨ�^ˮƽ���D��ĈD����߅�ӈD����ԭʼ�D����ͨ�^��ֱ���D�@�õĈD��
����1.1.2 �����V
�����D��������V��ͨ�^��ԭʼ�D����ÿ�����ؼ����~����S�C��Ϣ���Ķ��@���Єe��ԭʼ�D������V�D���˷�����Ҋ��ʹ�� M ��ʾ����ꇣ����� M �cԭ�D��ӱ� I ������ͬ�ijߴ硣�� M �е�ÿ��Ԫ���ɸ�˹�ֲ� N(μ,σ2 ) �a���r���Q���˹�D�������V��
�����D 4 �������V��ʾ������߅�ӈD��ԭʼ�D I �����g�ӈD���˹�ֲ��a�����S�C������������� M ������߅�ӈD��ԭʼ�D�� I �c����� M ��Ӻ����ɵ������V�D�� I′ �� 1.1.3 ģ�����V�D��ģ����ԭ���nj��D���е�ÿһ�����ص�ȡֵ���Þ��c��߅�������P��ȡֵ��������߅���صľ�ֵ����λֵ�ȡ��Q��ԓ����ȡֵ�c��߅���صķ����Q��ģ���돽������ γ ��ʾ��
�����o���D��ģ���돽 γ ��Ӌ��^���ÿ�����ص�ȡֵ������ͬ�Q���ˈD��ģ�������IJ�ͬ�����磬ʹ�ø�˹�ֲ�Ӌ��^��ȵ�ÿ�����ص�ȡֵ���Q���˹�D��ģ����ʹ��ֱ���D��ֵ����Ӌ��^���ÿ�����صĈD��ģ���������Q��ֱ���Dģ��[75] ����D 5 ��ʾ�������ԭʼ�D�� I ���҂��ǽ��^ģ���돽�� 2 (γ = 2) �ĸ�˹ģ�� (σ = 1.5) ���V���γɵĈD��ӱ� I′ ��
����1.1.4 �s�����V
�����D��s�Ű����D��ķŴ�͈D��ĿsС����������ÿ���D����L��������һ�£�������ȌW����ݔ��������Ҫһ�µĈD��ߴ硣���� 224 × 224 ����ˈD��s�����V����ȌW���н��������A̎���������o���D��ӱ� I��������D������ xi,j ∈ I,0 ≤ i,j < N��N �Q�������������ˡ��t�D��Ŀs�ſ������������ĈD�������c xi,j ���������S X �� Y �S���M�пs�ţ���ʽ(2)��ʾ������ (i,j) �����ص�ԭʼ���ˣ� (u,v) �齛�^�s�ź�������ˣ�kx �� ky �� X �S�� Y �S����Ŀs�ű�����
����1.1.7 �D��������V
�����D������nj��D��ӱ� I �IJ�����Ϣ�M��������ʹ��������ĈD��ӱ� I′ �H�H���� I �IJ�����Ϣ���D��������V��˼����ģ�M�D���È����еĈD���ړ��F��ͨ�^�˞����һ�����ʌ�Ӗ���D���M��“�p��”������“�p��”�ĈD��ӱ�����ݔ��o�W�j�D����ģ�ͣ�����ģ�͌W���D��Ě�����Ϣ����ֹģ���^�M�ϏĶ���K����ģ���ڜyԇ�ӱ��ķ������ܡ�
����1.2 ��W���g׃�Q���V
������W���g׃�Q���V��ͨ�^�{���D��Ĺ�W���g�M�е����V��������Ҫ�Ĺ�W���g׃�Q���V��������׃�����ɫ���g�D�Q�����У���W׃�Q�����D������׃�Q�����ȶȺ͈D���J�����ɫ���g׃�Q��Ҫ���� RGB �ɫ���g�c CMY �ɫ���g��XYZ �ɫ���g�� HSV �ɫ���g��YIQ �ɫ���g��YU �ɫ���g�� LAB �ɫ���g֮�g���D��[77] ����Ҋ�Ĺ�W׃�Q���V������� 2��ʾ��
����1.2.1 ����׃�Q���V
��������׃�����V��������׃�������ȶȺ͈D���J�����V�ȡ��D�������׃����ֱ�ӌ��D��ӱ� I ��ÿ�������c�M�о���׃�Q����[78] ��ʹ�� λ ��ʾ�D������׃�Qϵ�����t���^����׃�����V�ĈD��ӱ� I′ ����ͨ�^��ʽ(6)��ʾ������ 0 < λ < 1 �D��׃����λ > 1 �r�D��ӱ�׃����
����1.2.2 �ɫ���g׃�Q���V
������ɫ�D���У����õ��ɫ���g��Ҫ��RGB�ɫ���g��CMY �ɫ���g��XYZ �ɫ���g��HSV �ɫ���g�� YIQ �ɫ���g��YU �ɫ���g�� Lab �ɫ���g��[77] �� RGB �ɫ���g�Dz�ɫ�D��ӱ����ʹ�õ��ɫ���g���ڈD��ӱ���ʹ������ͨ����ʾ��ÿ��ͨ���քe��ʾһ�N�ɫ��RGB �ɫģ�͵ļt�G�{���N��ɫ�IJ��L�քe�� λR = 700.0 nm ��λG = 700.0 nm �� λB = 700.0 nm [77] ��RGB �ɫ���g�����c��ҕ�X�Ϸdz���������һ�N�ɫ����ͨ�^���N�ɫ��϶��ɡ�
����1.3 ���ڽyӋ�ĈD�����V
�������ڽyӋ�ĈD�����V����ͨ�^����yӋ�Wԭ�팦�D���M�н�ģ��ͨ�^���yӋ׃���M��׃�Q���_�����V�D�����P�I��Ϣ��Ŀ�ˡ����ڽyӋ�ĈD�����V�㷨����ֱ���D���⻯���V��С��׃�Q���V��ƫ�ַ������V�� Retinex �D�����V�ȷ��������У�ֱ���D���⻯���V��С��׃�Q���V�ɷN������鳣Ҋ[79] ��
����1.3.1 ֱ���D���⻯���V
����ֱ���D���⻯���V�nj��D��ӱ� I ��ݔ��Ҷ�ӳ������V��D��ӱ� I′ �ĻҶȼ���ʹ�� I′ �ĻҶȼ����н��ƾ���ֲ��ĸ����ܶȺ�������Kʹ�� I′ �� I ���и��ߵČ��ȶȺ����ĄӑB�������^��[79] ��
����2.4 �D�������V���Y
�����D�������V�������֮̎���Ǹ�׃�D��ӱ��˺��Ī����ע��Ϣ��Ӗ���ӱ��������Ę˺���Ϣ����ƽ������һ���̶����܉������W�j�ķ����������M��Ŀǰ�кܶͬ��͵ĈD���ϵķ�ʽ�����LjD�����о�Ŀǰ߀��Ҫ̎�ڌ��ƌW�A�Σ�ȱ�����ĿƌW��Փ�����M�н�ጡ�
����3 �������g���V
�����������g���V������Ӗ���ӱ��������M�����V���_������ģ�ͷ������ܵ�Ŀ�ˡ��������g���V�^�e�ڂ��y�D����g���V�����V�����ژӱ����^���ɂ��W�j�����a�����[�������M�С�ʹ�� Zi = F(Ii ) ��ʾ�D��ӱ� Ii ���^�������a���� F(∙) �@�����[���g������ Zi ���^�̡��c�D����g���V��ƣ��������g���V���������������V��������˺��Ƿ���F�_���Mһ���������׃�Q���������V��
�����������g���V�о��R����� 4 ��ʾ��Devries �� Taylor ��λ�W���� 2017 �� ICLR(The International Conference on Learning Representations)��������ڔ������������g���F�������V�ķ��� [102] ��ԓ�������������E���ɣ����ȣ�ʹ��һ�������ԄӾ��a���ğo�˺��Ĕ��� X �ЌW��ԓ�ӱ���ͬ���еı��_�����γ�ԓ�ӱ��������������� C ��Ȼ���ӱ�ͨ�^���a�����ɘӱ����������ٌ������M�����V����������������ֵ�ȡ�����^���V�����������������Ӗ���o�B�������������������Ӗ�����з������ԓ�������ڰ����������R�e���M���u�������ڻ����yԇ�Ќ��e�`�ʏ� 1.53%���� 1.28%��ԓ�����Ą���֮̎�nj��ژӱ����g�е����V�����w�Ƶ��������g�У��܉�������Ӗ���ӱ��ЌW���������ı��_߉���Ķ�����ģ�͵��`�
����Liu �ȌW���J���T�緭�D��׃�Ρ������ü��ȈD����g�Ĕ������V�����a���ĺ��픵���dz����ޣ���� Liu �ȌW����������������g�M�о��Բ�ֵ�Č����ԄӾ��a(adversarial autoencoder��AAE)[100] �D�����V������AAE ���Ԅ�׃�־��a��(variational autoencoder��VAE)�� �� �� �� �� �W �j GANs �� �Y �� �w �� AAE ���Ԅ�׃�־��a���е� KL ɢ�ȓpʧ��Q�����Ɍ����W�j���Єe���pʧ��
����AAE �c�˜ʵ� VAE һ�ӣ��ĈD��ӱ� I ���^���a���D�Q���[���g�е�����׃�� Z �����[���g�Ќ� Z �M�о��Բ�ֵ����ͨ�^��a���������V�ӱ� I′ ����ͬ�������댦���W�j�� Z ���M�вɘ� P(Z) �������е�һ��ݔ�룬ͬ�r���[���g�в�ֵ��� Z ��������һ��ݔ�룬Ӌ���·ݔ��֮�g�Č����pʧ��AAE �� CIFAR���������M���u����@������ĽY����
�����������g���V���ڈD���(raw image layer)�����V���������������[�،�(latent layer)��ʹ�ÈD�����V�ķ������ӏV���͈D�����V�о���˼·�����_韡�ͬ�r���о�[96] �������������g���V�������ڈD����g���VЧ�������@����δ���������ڈD����g���V���о��ɹ��������������g���M�Б��á��z���ơ�
����4 ��O�����V
������O���D�����V��˼·�nj�Ӗ���������������δ��ע����ͨ�^��O�����gʹ����뵽Ӗ���������У��Դ��_���U��Ӗ����������Ч����ʹ�� U = {uk } K k = 0 ��ʾ���� K ���ӱ��ğo�˺���������ʹ�� Φ(∙) ��ʾͨ�^ʹ������Ӗ�������� X �M���AӖ����ģ�͡�ʹ�� yk ′ = Φ(uk) ��ʾ�o�˺��ӱ� uk �ĂΘ˺������� (uk,yk ′) ���뵽Ӗ�������� X �У��Դ��_���U��Ӗ����������Ŀ�ˡ�
����Han ��[103] �W������˻��� Web �Ĕ������V�ķ������������D����Ч�������V��˼·���Y���£�(1)����ͬe��Ӗ���ӱ�����ͬһ�������б��У�����Խǰ�Ęӱ�����ԓĿ��Ŷ�Խ��Ȼ���ÿ��e���б����S�C�x��D��ӱ�����N���ς��� Google �M���ԈD�шD��(2)���d���е������Y����Ӌ�������d�D��ӱ��c�б��ЈD��ӱ������ƶȡ��M�����ƶ��ֵ�ĈD��ӱ������뵽���x���У���ӱ��˺��c�N�Ә˺�һ�¡�(3)ÿ���D���б����x�� Top-K ��������ƶȵ����d�D��ӱ������뵽Ӗ���������С�ԓ��������Ч�����ܵ��T��W�j�͈D���ṩ�����������ص�Ӱ푡�ԓ�����m����ȱ���~��D��ӱ����龰������һ�N���x��Ӗ�������V������
�������P֪�R���]��Ӌ��Cҕ�X�D��̎��Փ����ô�l��ei�ڿ�
����Berthelot �ȌW��[51] ��� MixMatch �İ�O���������V���������ȣ�MixMatch ʹ�ð�O���ļ��g�A�y K �����^�S�C�������V��ğo�˺��ӱ��Ę˺���Ȼ�� K ���˺����^�㷨��K�_���o��ԓ�o�˺��ӱ����A�y�˺������ʹ�� mixup ���g�S�C�İ�O�����V�@�Ô����������И˺����������x��D��ӱ��M�л���γ���K���V���Ӗ����������
���������� CIFAR-10�������ϣ�ʹ�� MixMatch���]�И˺��Ĕ����M�а�O���W����ʹ��ģ�͵ķ���e�`�ʽ��� 4����Ȼ�������� CIFAR�������ķֱ���̫���Լ� MixMatch �����H�� CIFAR ���������M���u�������ԓ�����ڸ߷ֱ��ʵĔ������ϵ�Ч���д��u����
�����@ȡ�����Ę˺���������һ�����F���M�r���^�̣�Ȼ���@ȡ�o�˺���ԭʼ��������һ�������������顣����O���������V�����܉o�˺��Ĕ�����������������ģ�͵����ܡ���ˣ���O���������V�LjD�����V��һ����Ҫ�о�����
����5 ̓�M�D�����V
����̓�M�D���������V��ͨ�^����ģ��(��Ҫ�����Ɍ����W�j����)ֱ�����ɈD��ӱ����������ɵĘӱ����뵽Ӗ�����У��Ķ��_�����������V��Ŀ�ˡ�ʹ�� I′= G(Z,y) ��ʾ������̖ Z ��N�ӣ�ͨ�^ģ�� G(∙) ���ɘ˺��� y ��̓�M�ӱ���̓�M�D���������Vͨ��ʹ�����Ɍ����W�j���������W�j����D��ӱ�������ģ�͡�
����Goodfellow �ȌW��[58] ������Ɍ����W�j��ģʽ���W�jģ��֮�gͨ�^�����W���ķ�ʽ������������ɾW�j�������|�����Єe�W�j���Єe�������S��������һ�Ɍ����W���ğᳱ�����m GANs ģ�͵ĸ�����Ҫ�Ǟ��˽�Q�����W���^���д��ڵ�ģʽ̮����Ӗ�����y�Ć��}��
����5.1 GANs��̓�M�D�����V
���������о�[62,104] ���� GANs ��һ�N��Ч�ğo�O���ĈD�����V���������� GANs �ĈD�����V��ʹ�� GANs ��������ģ�����鹤�������Д������Ϯa�����S���ĈD��ӱ����Դ��_���S��Ӗ�������ӱ���������ģ���ڜyԇ�����ܵ�Ŀ�ˡ�
����5.1.1 �������Ɍ����W�j
������ Goodfellow �ȌW��[58] ��������Ɍ���ģ�ͷQ��������Ɍ����W�j��ԓģ���״Ό��ɂ�������ĈD��ӱ����ɾW�j������b�e�W�j�ں���ͬһ��ģ�ͣ�ʹ�î���Ӗ���ķ�ʽ���߃ɂ�ģ�͵����ܡ�ʹ�ÈD 17(a)�������������Ɍ����W�j��ģ�͡�
����5.1.2 �l�����Ɍ����W�j
�������ژ������Ɍ����W�j[58] ȱ���ⲿe��Ϣ����ָ����Ӗ���^�̷dz����y�����˽o���������Єe�������~����Ϣ�ӿ��Ք��ٶȣ��l�����Ɍ����W�j���g(conditional generative adversarial networks��CGANs)[105] ����������ݔ��ˌ������ɘӱ���e��Ϣ����O����̖���뵽����ģ��������s������D 17(b)��ʾ�����Ը���ݔ��ėl����Ϣ���ɷ��ϗl���ĈD��ӱ��������m���ڈD�����V���摪��[106] ��
����5.1.3 �o����l�������W�j
���������܉��ṩ������o����Ϣ�M�а�O��Ӗ����Odena�ȌW������ڗl�����Ɍ����W�j���Єe���м���һ���~�����΄գ�������Ӗ���^��������ԭʼ�΄��Լ�����΄յă�����ģ���M���{�����@�������Q�����o�����Ɍ����W�j(auxiliary classifier generative adversarial networks��ACGAN)[107] ��
������ ACGAN �У������S�C���D�� Z �⣬ÿ�����ɵĘӱ����Ќ����Ę˺��������� G ͬ�r�������D�� Z �ʹ����ɵĘӱ��Ę˺� C ���a��̓�M�D�� Xfake = G(C,Z) ���Єe�������挍�D��ӱ� Xreal ��̓�M�D��ӱ� Xfake �Ĕ����ֲ����Д���ӱ��Ƿ����,�������t�A�y��ԓ�ӱ���e��ACGAN ��ģʽ���Ժ���������D 17(c)���~��ķ���΄յļ���������ɸ��������ĈD���Ҽ����o���������Ч������ģ�ͱ������}�����Y������ ACGAN �� CIFAR10�������Ϸ�ʴ_���_��ͬ���о������Ч����
�������� ACGAN �D�����V���о���ܵ��m���ԣ� ACGAN�����õ������I���ҕ�X̎���΄����P�о��С����磺Mariani �ȌW�ߞ��˽�Q�D�����Д������˺���ƽ��Ć��}����˔���ƽ�����Ɍ����W�j(balancing generative adversarial networks��BAGAN)[108] �������� ACGAN ����A���� ACGAN �е�“���”ݔ����“e”ݔ���ϳɞ�һ��ݔ������Q����Ӗ���^���������ٔ�r�ɂ��pʧ������_ͻ�Ć��}�����Y������BAGAN��MNIST��CIFAR-10��Flowers�� GTSRB �Ă��������У���ʴ_�Ա��F�� ACGAN �����㡣
����Huang�ȌW��[109] ���� ACGAN ģ������� ActorCritic GAN ��Q�D����������Ȕ�����ƽ��Ć��}��ʹ�� ACGAN ģ�͌�Ȳ�ƽ��Ęӱ��M���в�e�����V���U��ȈD��IJ�ԡ����Y���������ԭʼ�D��,���ߵķ�������ߴ�s 2 ���ٷ��c�Ĝʴ_�ʡ�
����Singh�ȌW��������� ACGAN ģ�͵Đ���ܛ���D�����V���(malware image synthesis using GANs�� MIGAN)[110] ������ʹ��MIGAN��Q���ڐ���ܛ�������^���Ў��˺��Đ���ܛ���D��ȱ���Ć��}��——Փ�����ߣ��ֳɄ� 1,4,5 ���� �� 2 ���w��ɭ 1,4,5+ ����־�s 3 ���� �Z 1,4,5 ����ٝ� 1,4,5 ���S���� 1,4,5 ����т� 1,4,5 �������� 1,4,5 ���ż��A2 �����pӡ1,4,5 ���_����1,4,5 ����Сë1,4,5 ��ꐱ���6+
SCISSCIAHCI