�l���r�g��2022-03-06���ٷ��Ӌ��C�QՓ���g�[��1��
ժ Ҫ�� ժҪ ���^ȥ��10����, �Ի���M�W���t�W�z���W������Ϣ�W�Ȟ�����������ƌW���о��I��, ��ǰ��δ�е����Lڅ��, �e���˺����Ĕ�����Ϣ. �@Щ������͏��s����������, �����N���ărֵ���Dz��ɹ���. ͨ�^���y��̎���ֶ�, �y�����庣��ԭʼ�������e�C���s���P��Ϣ. ��
����ժҪ ���^ȥ��10����, �Ի���M�W���t�W�z���W������Ϣ�W�Ȟ�����������ƌW���о��I��, ��ǰ��δ�е����Lڅ��, �e���˺����Ĕ�����Ϣ. �@Щ������͏��s����������, �����N���ărֵ���Dz��ɹ���. ͨ�^���y��̎���ֶ�, �y�����庣��ԭʼ�������e�C���s���P��Ϣ. ��ᘌ�������Ŀ�ҕ���о�, �������ڿ����ˆT�����s�����M�ж�Ƕ��^�첢�@ȡ��Ч��Ϣ. �������Խ��, ���s��Խ��, ��ҕ����������Ч��Ϣ�ھ���l�]�����þ�Խ��. ����ͨ�^���e��������C�����ĬF��Ĕ���Ҏģ�͔������L����, �f�������о��I�����M����r��, Ȼ����������ĽM����������ҕ�������c�����������ҕ������Ҫ�Ժͱ�Ҫ��. ���Ŀ��Y�������ƌW�о��I���в�ͬ���������Ŀ�ҕ���о��Mչ, ���ӑՓ��Ŀǰ�������ҕ�������R������, ��������ܵĽ�Q����.
�����P�I�~ ��������Ϣ�W��ҕ��
����2005���ԁ�, �S����ͨ���y���g�IJ����M�����V������, �����ƌW�����˴��r��. �Ի���M�ƌW�������t�W�I�������������ƌW�о��a���ͷe���˺����Ĕ�����Ϣ: �W��������Ϣ�W�о��� (European Bioinformatics Institute, EBI)Ŀǰ�惦�ˌ���20 PB�Ĕ���, ���л���M�����sռ2 PB, �@һ�����S����һ���y���g�IJ���lչÿ��ɱ����L[1]; ��ͨ���y����(Sequence Read Archive, SRA)���������������\�g��Ϣ����(National Center for Biotechnology Information, NCBI)����Ҫ�ĸ�ͨ�������惦��, Ŀǰ�惦�Ĕ����������^��3 PB, ����l���Ĕ������_��1640 TB[2]; ����, ��ǰ���������Ļ����a���C��——�A������о�Ժ(Beijing Genomics Institute, BGI)ÿ��a�������ˡ�ֲ�����������ڃȵļs6 TB����M����[1].
�������H�ϵĶ��������о��Ŀ�a����ʷ�oǰ��Ҏģ�������. �������g���ȫ���z����Ϣ, �����ƌW����1985����������������MӋ��(Human Genome Project, HGP)[3], �@һӋ�����H���w�� 99.99%�������M, ���x�����w�����ܴa��“����֮��”, �����Ƅ��������ƌW�����\�g�Ļ��A���о�, ���M��һϵ�пƌW���g�Įa���Ͱlչ; 2004��, ���ˌ�����һ��DNA�о����g��������{��������ȫ����Mˮƽ���о��đ���, “DNAԪ���ٿ�ȫ��” Ӌ��(Encyclopedia of DNA Elements, ENCODE)����, �@һӋ����ʹ����32�����ЙC����442���о��ˆT�@ȡ�������˳��^15 TB��ԭʼ����[4]; ��2005�������, �����������Ұ��Y�о���(National Cancer Institute, NCI)���������������M�о���(National Human Genome Research Institute, NHGRI)��ͬ�l��İ��Y����M�D�VӋ��(The Cancer Genome Atlas, TCGA)[5], ͨ�^��������M���gƽ�_�������@ȡ���^ 800 TB�������ęn�Y��, ���\�ࡢ�ί����A�����Y�����˶،��Ļ��A; 2010��, �С�Ӣ���¡����ȇ���ͬ�����ˇ��Hǧ�˻���MӋ��(1000 Genomes Project), �����ֹ�a���Ĕ������_��50 TB, ���а�������ȫ��27����Ⱥ��2500���˵�ȫ������M��Ϣ[6].
��������y���g���M���ٶ�֮��, ���h��Ӌ��C�I�����Ħ������[7](�r��׃�r, �����·������ÿ18��������һ��). ��1990�ꆢ�ӵ������MӋ����, �����W���С��յȶ������Һ͵^���^200���ƌW��, Ͷ���˳��^10��ĕr�g�ͼs30�|��Ԫ��������ȫ����M�Ĝy��; ���F��, �H��һ������ҵĔ����о��ˆT, �Ϳ��ڔ��܃�������ȫ����M�y��, ��ԇ���ɱ��t�ɿ�����1000��Ԫ֮��. ��˾���M��, ���H�o�����ƌW���о������˾�ęC��, �ڴ˻��A�������Ч̎���ͷ����@Щ�y��, Ҳ�o���I��ȵ��о��ˆT�����˾������.
������DNA���Д���������ĺ��������ǘ��������ƌW�о�����Ҫ�M�ɲ���, ͨ�^����������Ϣ�W���g�M�д��о�, �����[���ڴ��������W֪�R�ɞ鮔ǰ���\�g�lչ����������. ���y�Ļ����ı��Ĕ���̎����չʾģʽ�ѽ������Ƽs�ˌ��������ƌW���Ľ��x. ���ڿ�ҕ�����g����Ϣ�ھ�ɞ�һ�N����Ľ�Q;��. ��ҕ���nj����ィ������ģ�ͻ�������D���һ���^��1). ͨ�^��ҕ��, ����ķ�̖��Ϣ�����D������������ĈD���ģ��, ���⽻��ʽ��ʹ�����S�о��ˆT�IJ�ͬ�Ŀ�ҕ���Ƕȁ�̽���[���ڴ���IJ�ͬģʽ���P. ��ҕ�����Џ���Č����s�����D�����������Ϣ������. ��������s��������T�����c�Q���˿�ҕ������Ч������������IJ��ɻ�ȱ���ֶ�. �������ҕ�������ڬF�е�Ӌ�㼼�g, ��һ���r�g�Ȯa��ҕ�X���Fģ��, ���ڴ˻��A�ϱM���ܵ�����������, �Ķ��ӏ��Ñ��w��Լ�������������Y�����J֪����.
����1 ���������������Դ
������������˾��Ђ��y��4“V”�����c, ����������(Volume)������̎���ٶȿ�(Velocity)������Դ��׃(Variety)���N���rֵ(Value)��[8], ߀���������еĔ������s��(Complexity)[9]. ������W�����, ���s�̶Ȍ������I��a���Ĵ�Ҏģ�����c�����ƌW�I��Įa���^���_��. �ڸ���������, �������������ĽY����ע�, ������W����Ŀǰ���v�s�y�������ؽM������. ���˺��εĻ���M�y����, ����W�ҕ�ۙ�S�ͬ�ļ����ͷ��ӳɷ�, ԇ�Dʹ�ø��N�ֶ�Ū�����а����ď��s�Pϵ. ����, ����������������Բ�ͬ�Č����͙C��, ʹ���˲��M��ͬ�ą����˜�, �a���Ĕ�������S������, �����@Щ�������ܲ��ò�ͬ�Ĵ惦�Y��(��narrowPeak, BED, SAM ��), ᘌ���ͬ���о�����(��������С������|�����Pϵ����Ⱥ������), ��Դ�ڲ�ͬ������(��y���t��ӛ䛵�). ��ͬ���ą����˜ʡ��خ��ļ����M������Լ��o���Y�����惦��ˎ��̎���^�̵��T�����ض��������������s�Ե�ԭ��. �������ҕ���ĺ��ľ���������Ч���㷨�����@Щ�����ď��s��, �Ķ��������[��������WҎ��������չʾ�o�Ñ�, ���������D�Q�@Щ���s�����ĸ�ʽ, �t�ǔ�����ҕ���OӋ�ĵ�һ��, �����Ԕ�����Դ�����˽���������s���ӵĸ�ʽ����.
��������, �y���g���w�ٰlչ�������I���ṩ�˔�Ŀ����Č��F�YԴ. Ŀǰ�ڶ����y���g���V������, �ڶ����y��a�������fӋ�Ķ�����, ����ƴ���㷨���@Щ��������ȫ����M�����ȽM�b����, �Ķ��M���Mһ���Ĕ�����������[10]. �����ֹ, ���d�Ćμ����y���gһֱ���J�������ֵ���Pע�Ĝy���g, ���y�Ĝy�������˼����g�IJ��, �õ��ĽY���H�H��һȺ������̖��ƽ��ֵ, �����چμ���ˮƽ��ȫ����M�M�ДU���c�y��Ćμ����y���g, ���H�ڻ�����_������y������, �����܉�z�y�����_���^�͵Ļ��Ǿ��aRNA, ��˾��кܴ�ă��ݼ��lչ���g[11]. ����֮��, �μ��� RNA�y��(single-cell RNA-seq)ʹۙ���������D䛽M�ɞ���� [12], Ⱦɫ�|���߹�����y�� (ChIP-seq)[13]�Ȍ��g������֧���ˌ�����M�����Ĺ�����ע�. �@Щ��ͨ���Ĝy���g, ���о��߰l�F�c�������P�Ļ�����׃�����о�ij�����͵������D䛽M��ijһ�l���µļ�����B�Լ���DNA�ϵ����|�Y��λ�c�M�ж�λ�ȹ����ṩ�˱����c֧��, Ȼ���S������Ҏģ������, �y����̎���ͷ�����u�ɞ�ƿ�i.
�������, ����оƬ���g��ʹ�����^ȥ�Ĕ����Юa��������Ĕ����YԴ. ���ˌ��F������M���������������|������ȽM���и����Ĵ�����Ϣ�M�п��ٜʴ_�ęz�y, �о��ˆT�ڹ��wоƬ���昋�����͵����ﻯ�W����ϵ�y. ��ǰ������оƬ��Ҫ�֞����оƬ������оƬ�ɷN���[14]. ���y�����o�B���s�����g����A�����оƬ��Ҫ�л���оƬ(DNA Microarray)������оƬ(Protein Chip)��оƬ����� (Lab-on-a-chip)����ʽ[15]. ����, ����оƬҲ��DNA ���ܶ��c��s�����g, �Ժ���̽ᘻ��a�s�����g����A������, ������DNA���Мy������_��������������Լ�������B�Է������о�Ŀ��; ����оƬ���������|���Ӻ��������ӵ�����ö�����; ��оƬ����Ҍ��������̼��s���γ��͵ķ���ϵ�y. оƬ�c������ӷ������a������̖��Ҫ������оƬ����x, ��ͨ�^���Pܛ�������ɼ����ĸ������c�ğɹ⏊����̖������λ����Ϣ���γɵĈD����@ȡ���P��������Ϣ. ����оƬ�����w���Ƽ��g����A, ��Ҫ��ë�����ӾоƬ��PCR����оƬ����ʽ[15]. �����, ����оƬ���g�ڻ�����_ˮƽ�z�y�������\�ࡢˎ��Y�x�����w���t���R���������\����ί��������л���l�F�Լ������ܴ_�J���t�W�c����W�I��õ��V���đ���.
�����ٴ�, �����|�V�������ƌW���о������˾��ؕ�I, ���H���J���Ǵ�Ҏģ����ͨ���b����ʮ�f���������������ӽY�������x����, ���Ҍ����о�����-���ȴ����֮�g������á����g������Լ�������_ˮƽ��׃�������ܴ�Ď���. �|�V����Ҫԭ�����Ȍ���Ʒ׃���B���x�ӻ����, �ٰ����|�ɱ�(m/z)�M�з��x, �Ķ��ɹ��@ȡ��Ʒ���|�����������Y������Ϣ[16]. �ګ@ȡʹ���V�D�����б�����ʾ�Ĝy���Y����, ��Ҫ�M���Mһ���Ĕ�������. �����b�������|�ķ���, Ŀǰ���õ����|���y�b���� (Peptide Mass Fingerprinting)�������|�V�Ĕ����������b����(MS/MS Database Searching)���ֶ�[17]. �|�V�������g���Q�������|�M�ĺ��ļ��g, ����� Nature�Ϲ�����������|�M�݈D���ǻ���16857���|�V�������Y��������[18]. ���|�o���������-�w�Еr�g�|�Vϵ�y(VITEK®MS)��������FDA���ʵ��ׂ����ڙz�y�������|�V�z�yϵ�y, �����ڽ�ĸ�����²������R�������b��, �@Ҳ�ǵ�һ�N���ڔ���犃șz�y�²�������t����е[19].
��������, ͨ�^���N���M�ֶΫ@ȡ���c�������P�ĈDƬӰ���Y��Ҳ�����S������. �����w�ȴ����������|��RNA�Լ�DNA�ȷN������������. �S���@�R�������ȸ߾���˃x�����g�IJ���lչ, �ƌW�҂����H�܉�ͨ�^�͜�����@�Rֱ���^�쵽�����|���������Ӿ�����ԭ�ӵĽM���Y��, ������u����ֱ���^�yӛ䛵����w�M�������������ڕr�g�����g�S���ϵĽY��׃���������g������õĄӑB����. Ŀǰ, ����˹̹����W�о��ˆT���� “�̓ȸQ�R”�����������ѽ����F���ڲ��ƉĻ��w���^��M������r��, �L�r�g�،����w���X��Ԫ�M���^�y[20]; ������W�_�l��“���������ܼ�����ɢ�����”���g�ɹ����خ��Ԙ�ӛ�˻����֬����ǡ������|����ȳɷ�[21]; �����~�s��Ȫ�ی���Ҍ����Ә�ӛ�ֶ��c�@�R���g��Y��, �������˵�һ�����w�����w���[��������ӵ�Ӱ��ӛ䛹���[22]. ͨ�^�@Щ���¼��g�ֶ�, �ƌW�҂��������еõ����м������M���е����|�͏ͺ�������Pλ��, Ū�����w���ЙC��śr. ���, Խ��Խ��ǽY�����ĈDƬӰ��ؽ�����������ϡ�������չʾ.
�������, �R������Ҳ��һ�����ɺ��ԵĔ�����Դ. �H�`�����Ї����t�ƌWԺ�ďV���T�tԺÿ��a���Ĕ��������_��70 TB2), �����ȫ�����R��������������һ��, �䔵��Ҏģ���Dz��ɹ���. �F�е��R���t�W����������Ӳ��v���t�WӰ���Y���Լ������z�顢������Ƭ�z�������W��Ϣ��, �@Щ�R����Ϣ�������ӡ����ࡢ������, ���������漰�����[˽����˾����_ͻ�Ȇ��}, ��֮��Щ����֮�g�y���P, ��ɘ˜ʻ���ʩ�����y. �@�N�Y�����c�ǽY������ʽ��������c, ʹ���R����������������׃�î������y[23]. �����ھ��@Щ�t�������Н��ڵărֵ, һЩ�R���Ϳ��ЙC�������t�������M������, �����R��ԇ���Ĺ����ͷ���ƽ�_. �����ĸ����tԺͨ�^�R��������Ϣ����ϵ�y�����`��������Ҏ���������ֻ�, �����Ĕ���ͨ�^�����D�Q���^��, ���Mһ�������ڲ�ԃ�z�����yӋ�����͔����ھ���, �Դ˫@ȡ�µ�֪�R, �Ķ�������Ч�،��R�����`�M��ָ��2). �����R���[���W��(American Society of ClinicalOncology, ASCO)���µ�“CancerLinQ”���S�о��ˆT�M�롢�L���ͷ����������Y���ߵIJ���[24]; ���͵�����\���I��Ҳ����Ϣ�����ṩ�˘O��ı���. �������R���������������Ì���������ڿ����ˆT���t�W���Ҍ���Ҏģ��������Ⱥ�w�ί���r�M�з���, �Ķ��鹥�����y�s�Y�ṩ���C.
�������P֪�R���]���Ք�����ҕ��Փ�ĵ��ڿ�
�������������ׂ���Ҫ���������Դ����, ���͵ļ��g�ֶβ���ؕ�I�����F���YԴ����, �������µ���ʽ�ɹ⼼�g[25]���Ԍ��F���١��ʴ_����ͨ���،��[����־���M�Йz�y, ���ⲻͬ��͵ăx���O��Ҳ�������I���ṩ�˲����Ѓrֵ�Ĕ���. �S���Ĕ�����Դ�@ʾ����������H����Ҏģ����, ��͏��s��׃, ���������w���g�ϽY����λ���S�r�g����׃�Q���Ƅ�. ��Q�@Щ�����Ĵ惦ֻ����������΄�, ������Ҫ����ʹ���@Щ����. ͬ��, ��������M�п�ҕ���Ǟ��˸��ӳ�ֵ��ھ�������Н��ڵărֵ, ������OӋ��ҕ�����ߕr����܉��Ԕ�����Դ������, �Ĕ���Ҏģ�����s�ȡ����g�Ժ͕r�g׃�Q���@4������ᘌ�Ŀ�˔����M�п��], ��ʮ�������ڏĔ����Ы@ȡ��Ч��Ϣ.
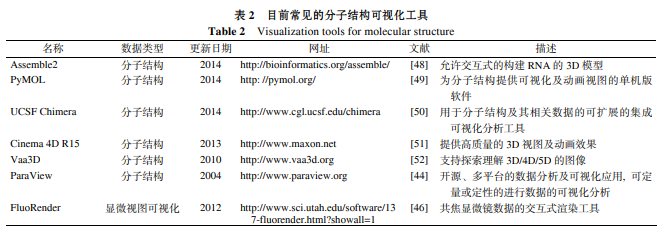
����2 �������ҕ����ͼ��F��
������ҕ����������ķ������P��Ҫ, ������������ԁ���, һ����r�H�{���ֺ��y����������д��ڵď��s�Pϵ. ��ҕ�����H�����Á��M������չʾ, ���ǔ��������ĵ�һ������, ��������M�����õ�ֱ�^��������չʾ���Խ�ʾ���������ڵ��e�C���s���P��r, ���@һ�c�������������y�c��ҕ�����ᲢՓ. ����ε�Excel��ӱ���Google �ęn��R, Pandas�ȽyӋ���̼ܘ�, �ٵ�D3.js, Prefuse �ȿ�ҕ�������, �@Щͨ�Ô�����ҕ����̎�����߶����Ԟ锵����������Ϣ�ھ��ṩ�ܺõ�Ӌ��C�ֶ�. ����ᘌ��ڲ�ͬ�Ĕ�����ͺ�Ŀ��, �����I��ӿ�F��һ�����_Դ������Ŀ�ҕ������(�D1), �@Щᘌ������о��ˆT�_�l�Ĺ�����������, ��������Ŀ��ٷ����ṩ�˱���.
����2.1 �y��
�����y���g������оƬ�ṩ�˴����������w�е� DNA, RNA, �����|�ȴ���ӵ��S����һ�������YԴ, �F�еĻ���M�g�[��������ͬ�������@Щ�����M���ˏļ��������^��չʾ. �Ԯ�ǰ��鳣�õ� UCSC Genome Browser[26]����, ��֧�ֿ��Ա��Ȍ�������M�ϵ��κΔ������, ���D���ڷ���������Ⱦ��Ƕ��W���. �����ڻ���M������չʾģʽ�w�F�˴��F��g�[�����е����c: (1) ��Ⱦɫ�wλ�Þ������Ļ���M����ҕ�D; (2) �ԅ�������M��˜��ṩλ�������S; (3) ����trackչʾ; (4) ���õĽ����ԺͿɶ�����, �ɸ����Ñ������M���b�d���[�ؔ�������. �����@Щչʾ������, ��ͬ�Ļ���M�g�[��Ҳ�����Լ����صĹ���. GenomeView[27]�ṩעጾ���, ����չʾ��ע���Ϣ, �M�ж����бȌ���������ƥ�䡢�����бȌ��Լ��������Ա��@ʾ�ă���; ����̽�����ͼ��ɔ������Ŀ�ҕ������ (Integrative Genomics Viewer, IGV)[28]��֧�ֶ�N������͵Ľ���չʾ, �����y�����бȌ���������_�����Ϳ�ؐ������(�D1(e))��.
�������ڲ�ͬ�ĽM���D䛽M�ı��_����������ڽyӋ�ֶ��M�о��, ����Ҫʹ�ß�Dʹ��Y���ʬFֱ�^��չʾ, �����Խ��, ��õ��IJ�ͬ���_ģʽ߀���Mһ�����չ��ܸ����̶��M�з���ԈD�λ���ʽ��ʾ���O�z�ĽY��, ��Gitools[29]������Ĵ���߲����˟�D����ʽ������M�����M�м��ɻ�������չʾ, �˹���ͨ�^����KEGG, Biomart����������_�������֪�R������, �ṩ�������������P�Է����Լ��@����Ӌ����S���ķ����ֶ�, ͨ�^���������^�V���Ƅӡ��ۼ�����������ҕ������עጵȹ������Sʹ���߽����Եط����Ϳ�ҕ����S����.
��������, �y���Ŀ�ҕ�����ܕ��������������ھ������Q���Ե�����. ����, �κ�������B�� (SNP)������ȱʧ��ӛ(InDel)�Լ�����M�Y��׃����һ���������H���Pע�ă���, ���������c���s�����İl���lչ���������Pϵ. ����, ����M�Y��׃���������롢�h�������á���λ�������Լ���ؐ��׃���Ȳ�ͬ�����, ÿ�N���ʹ����M�a����ͬ�ĽY����׃. ���ڸ�Y��׃���ď��s��, �Լ�����������M�Y�����е��؏���������, ���H�{�F�е��㷨���y��ȫ���_�ؙz�y��ÿ�N��͵�׃��. �e��, �Y��׃����������������е��e�`��λ, �M������С�߶ȵĶ��B���A�y�e�`, ���ͨ�^�ṩ��ҕ�����߁������о����M���˹��Д��ڽY��׃���ęz�y���R�e��׃�ò��ɻ�ȱ[30]. Ŀǰ�����T���������չʾ��̽���Y��׃���Ŀ�ҕ������, ������\���ڸ��N����ϵ�y�ϵ�ᘌ��Y��׃���ļ���ܛ��inGAP-sv[30], ���H�܉����^�͵ļ���Ը��ʙz�y�����s��׃�����, �����ṩ���ѺõĿ�ҕ���ӿ�, ÿ�N��ͽY��׃������ģʽ�M�И��R, ͨ�^�ғ���˿ɫ@ȡ�P���ض��x�L��Y��׃����������Ϣ(�D1(f)). ����֮��, inGAP-sv���Sʹ���߸��������������`���O���@ʾ�y������е����ͺ��B�����ɫ, �Ա���õ؞�̽���Y��׃���ṩ����. inGAP-svᘌ��ڽY��׃���ṩ�R�e����ҕ����עጡ��˹�����һվʽ�ķ���, �@�N����ҕ�����ھ��һ�w, ע���Ñ��w�ȵĹ����OӋ��ʽ�Aʾ��δ����ܛ���_�l����.
����2.2 ���ӽY������
�����Y����������W�nj������ͻ��W�c����W���B�ӵ�һ�T�P�I�W��, ����Ҫ�۽���3D��4D���s�Π�����Pϵ���о�, �ɹ��ӛ���@�^���Լ������ȼ��g���@һ�I���ṩ���S����ҕ�D����, ����������ڷ��ӽY���Ŀ�ҕ���������о��^�������˘O�������. �Կ�ҕ��ܛ��ParaView[44]����, �����Sʹ����ͨ�^���ԺͶ����ļ��g�ֶΌ������Ĕ��������ٽ���3Dҕ�Dģ��, ������ĽǶȌ����ӽY���M���^��. ���ڵ����|�ȴ���ӽY���������s, ��Ȳ���λ���Pϵ��Ҫ������Ӌ���YԴ, ���3Dҕ�Dܛ��������2Dչʾ������Ҫ���Ӹ�Ч���㷨�OӋ, �����ܵ�Ӌ���O���Լ��߷ֱ��ʵ�չʾ��Ļ. ������������Ҏģ��������̎������, ParaViewʹ���˷ֲ�ʽ�惦Ӌ���YԴ, �����\���ڳ���Ӌ��C�ρ팦�f�|�μ��Ĕ������M�п�ҕ������. ����ParaView, Amira[45], FluoRender[46]�ȹ��߶������Á�g�[���� CT, MRI���@�D��, �Լ����F�����ӽY����3D ߀ԭ.
�����@Щ��Ӌ��D�ΌW����A���_�l��ܛ�������mȻ�Ը��龫���ʴ_��չʾ��ʽȡ��������ģ��, ���Džsʧȥ���c���팦�ӽ��|�r�a���Ĺ��е�ҕ�X�S����, ���@�N�|�X�ͱ��w��������������3Dģ�ͺ��M�����������ṩ���P�I�ľ���. ��˹��I�I������w��������u�������ڌ����ӽY����߀ԭ��. Ʃ��������A��W�c��������ِ����W�о��ˆT�Ի���z���w�S���͌m�i��������ԭ����, �ھ��ʵą���������, ����һ�_3D������ӡ�C�ɹ���������c��Ȼ�[��ʮ�ֽӽ����[��ģ��[47].
����2.3 �Pϵ�W�j
���������I��������������ӻ��������x;�����{�����úͻ�����_�ȬF��Ĵ��ڴ�ʹ�˸��N���ӵ��Pϵ�W�j�Ĵ���, �S���ƌW�҂����@Щ�^�̵������о�, �˂�������s�ȵ��˽�Ҳ�ڲ�������. ����W�ҽ�����Ҫ�������������Pϵ�ď��sϵ�y�߾S�����M�з���, ��ˮa���˿��Ԍ����N�W�j�Pϵ�M�п�ҕ����ܛ������. Ŀǰ���õď��s�W�j��ҕ��������Cytoscape[53]��R�е�igraph���Լ�Perl�е� GraphViz����. Cytoscape����һ����c��ģʽ����A�M�оW�j��ҕ���Ĺ���, ���ṩ���A�Ĺ��ܲ��ֺ;W�j��ԃ����, �����܉��������������Pϵ�ӑB���ɿ�ҕ���W�j. �������ӡ������|�ͷ���ʹ���c��ʾ, ���c�g�Ľ����Pϵ���B��Ҳ����߅�M�б�ʾ. �@�N��ʾģʽ�����˷����g����õľW�j, �m���κη���ϵ�y�ĽY������Pϵ, ���S�������|��DNA �������������������Ҫ���õķ��Ӕ������P����, �γ�����ľW�j�Y��. ����, R�е�NetBioV, Gephi[54](�D1(c))��ܛ������������Ϣ�W���ṩ�ˌ����c�B����͵ľW�j�Pϵ��ҕ���_�l����.
�����S��Ӌ���ֶε��Mһ���lչ, �W�j�Pϵ��3D��ҕ����ʽ��u�lչ����. BioLayout Express3D[55]����������2D, 3D���g�ȵĿ�ҕ������w�{��̽���ͷ������͵ľW�j�Pϵ. ��ܛ���Ɍ������|���������������Ե��Pϵ�γɵľW�j�M��չʾ, ���˂��y�Č���л�����_�����M�нyӋ�W������ķ���, �D�������P���u�������x���_���g��������, �Ķ��γɔ��������ľW�j��ʽ , ���Ҵ˹����� OpenCL���п�ܾ���, ��ֿ��]���W�j�Pϵ3D��ҕ���r�����Ӌ���YԴ���D��̎�����g֧�ֵȆ��}. ��2D��3D�h����BioLayout Express3D�ṩ����3������; (1) ���D����Ƅӡ����D�Ϳs�Ų���; (2) ���c��߅�Ă��Ի�����, �����S�O���ı��˺��Լӏ�ʾ���; (3) �����ɫ��3D�����ͶӰ�����c����y�����@ʾ���ݿ��M��ƫ���O��, �Ա���õ،���ҕ��Ч���M����Ⱦ.
����2.4 �R������
�����mȻ��Ӳ��v��ʹ�÷����ڲ���ؔU��, ���Dz��yһ�Ę˜ʡ��ǽY�����Ĕ���ģʽ���о��߫@ȡ�����ί����挍�Y������˺ܴ���ϵK. �ƌW�҂�Ҳ�_ʼ����̎���@�����}, ����������[��������Ŀ�˵�Flatiron��������һ������, Flatiron��Ļ����ƶ˵�OncologyCloud[63]ƽ�_�ۺϲ��D�Q�ˁ��Զ������Ļ�����Ϣ��ˎ����Ϣ�ͻ��֏͠�r�Ȕ���, ���ṩ���������Ěw�{����(�D1(d)), �ɴ��t�����H�܉�ͨ�^OncologyCloud����ͬ��ߵ��ί��Y��, ߀��ۙ��������ͬ�ί��������a�����R���Y��. �@��һ���ṩȫ����[�������ռ���������ϵ�yҲ���[���I��Ļ��A�о��ṩ�˘O��ı���; “���Y�����ƌW�f��CEO�A����(the CEO Roundtable on Cancer)” �Ƴ���PDSӋ��(Project Data Sphere)[24], �Lԇ����һ�����Y�����R��ԇ�������ͷ���ƽ�_, ��������ِ�Z�ơ��x���Լ���˹�����șC����ͬ�ṩ, �@Щ��������ȥ�����߂�����Ϣ���M���˽yһ��̖. �����f���T��ijЩҎ���ƶȵ�Ӱ�, �����t�����������Ϻ��ھ�߀��r�g���lչ��Ҏ��. �����ɷ��J����, ���ί���Ϣ�R����һ���M�з���չʾ�����˼����������ɺ�ҕ������.
�������������U���Ŀ�ҕ������, ������ͬ������߀�������ܶ������Ŀ�ҕ����ʽ (�� 1~4). �� �� , Chimera[50](�D1(b))�����ӽY���Ͱ����ܶȈD�V���������b�䡢���бȌ���܉�E�ڃȵ����P������������, �a�����|���ĄӮ�Ч��; ���ڲ�ͬ�|�V�x���a���ĵ����|�V��ʼ������ʽ��ͬ, �������|�M�W�|�V���������нyӋ�W�㷨�Č��F�^�ڏ��s, ������ʾ��ҕ����������ȡ��ҕ�������ҕ���������|�|�V�����ķ���ʮ����Ҫ; ����֮��, ߀����ᘌ���SNPչʾ�����^�z���W���ṩ�ĺ�С�w��λ���M�������Y���Ŀ�ҕ��������Ⱥ��śr�Ŀ�ҕ������������D����T����헌��ܵĿ�ҕ��ܛ������. �������ҕ�����߷N���, ���˸��õ؞��ھ���Ч��Ϣ��䁉|, ���_�lڅ������нyӋ�������ܵ�һվʽ���ɹ��߿��n. ����, δ�����������ҕ�������ڽ����ԡ����^�ԡ������Է��������Խ��Խ��.
����3 չ����δ��������
��������������Լ������c, ���H����Ҏģ����, �ֲ��ڲ�ͬ�ĽM���C��, ���ҾS�ȸ�, �����������ԺͲ��_���ԏ�. ���ø��N���g�ֶΫ@ȡ������������Ŀ��, �������M�п�ҕ��Ҳ����Ŀ��, ������Ŀ����̽�������ı��|, �l�Fδ֪��Ҏ��, ����Ľ����Ҹ�����, ����ھ��[���ڔ�������ĺ��x�ɞ�������Ϣ�W�҂�һ�µ�Ŀ��. ����˽�Ŀǰ�ڷ���������ĵ�·�ϴ��ڵ�һЩ�����ڵĽ�Q����������Ҫ�����x.
��������, �F�еĺ���������д��������������������, ���a�����ĽM���C�����Ԍ�ԭʼ�����M�И˜ʻ�̎�����|��. ����, �Ɍ��������T�e�, ʹ�ýyһ�Ĕ����惦�˜ʡ�Ҏ���. �������A̎���ֶο���һ���̶��Ͻ��͔���Ҏģ�����s��, ��ʡ�惦���g��������ݔ�ɱ�, ͬ�rҲ����ߔ��������x��, �p���о��ߌ������M����ͬ̎������Ҫ��Ӌ��r�g���YԴ��.
�������, ���ڮa���Ĕ��������ֲ��ڲ�ͬ���о��C��, ��Ό��F���������Ĺ������о��ˆT���ձ����R��һ������. �F�еķֲ�ʽע�ϵ�y(DAS)[69]�ṩ��һ�����ڵĽ�Q����. �����x��һ���Á����Q������|���м���עጵ�ͨ�Ņf�h, �ڴ˅f�h��, ���ھW�j�Ŀ�ҕ��ϵ�y�Ɍ��Fͬһ�������h�̮��طֲ�עጔ����Ŀ�ҕ��.
��������, ��������еď��s�����Խo�����ھ��ܴ����y, ����ڌ������������M�п�ҕ��ǰ, ����ͶӰ�����N���;S�ȵļ��g���V������. �c��ͬ�r, ���ҕ�X�����J�ԡ�ʹ�����挦չʾ����r���Ɣ���������Ϣ�������������ض���Ҫ���Կ��]. ��������M�п�ҕ���r, ��ҪӛסĿ��ʹ��������, Ŀ������Ϣ��չʾ��̽��, ����һζ����ҕ�X���^. ���_�l������Ŀ�ҕ�����ߕr, ��Ҫ�M�������ܛ����ƽ�_��������, ��ֿ��]�Ñ����w��, �ṩ�ѺõĽ�������.
��������, �����ĕr�g�Ȍ���Ҏģ�����M��̎������ҕ�����������Ҫ��. ����ͨ�^ʹ�Ã����㷨������Ҏģ�Ϳ�ҕ��Ч���M��ƽ����, ߀�������벢��̎�����g. �ڌ����ɔ������M�п�ҕ���r, �Ɍ���ԃ̎����ɢ�ڶ������й��c��, �Դ˿s���\�Еr�g, �ӿ��ҕ�����ٶ�.
��������ǰ������, ���ڂ�ݔ������ľW�j���A�Oʩ�Ľ��O�������Ĵ惦��ʽ���T��涼������һ�������y. �mȻ�ڷ���������ĵ�·�����R���T������, �����@Щ���r�����y��������ֹ�ƌW�҂�ǰ�M���_��, �����ƌW�������漆��K������һ���������ˆT��Ŭ���±���ȫ���_.——Փ�����ߣ����բ� , ���ע� , �w���c��*
SCISSCIAHCI