�l���r�g��2022-04-14���ٷ��Ӌ��C�QՓ���g�[��1��
ժ Ҫ�� Ҫ: ᘌ��D��������ȡ������ȡ��һ�������ܺܺõر�ʾ�D��Ć��}������˶��S�����b�e�����ͅfͬ��ʾ���沿�R�e����. ԓ��������ͨ�^���S�����b�e����( Two-Dimensional Linear Discriminant Analysis��2DLDA) �քe��Ӗ���ӱ�����gɢ����ꇺ��ɢ�������ȡ������֮
����Ҫ: ᘌ��D��������ȡ������ȡ��һ�������ܺܺõر�ʾ�D��Ć��}������˶��S�����b�e�����ͅfͬ��ʾ���沿�R�e����. ԓ��������ͨ�^���S�����b�e����( Two-Dimensional Linear Discriminant Analysis��2DLDA) �քe��Ӗ���ӱ�����gɢ����ꇺ��ɢ�������ȡ������֮�����õõ��������ؽ��D������g̓�M�D����̓�M�D��. ��Σ�����g̓�M�D���̓�M�D���ԭʼ�D�����Åfͬ��ʾ( Collaborative Representation��CR) �㷨�M�е÷�. ����üә�÷��ں��㷨�������÷��M���ں��ԫ@����K�÷֣���������K�÷��M�ЈD���R�e. ԓ�������H��Ч�������˹��պͱ��錦�沿�R�e��Ӱ푣�ͬ�r�����@�õ���g̓�M�D���̓�M�D���cԭʼ�D���a����Ч������沿�D���R�e������. ���Y��������ԓ�����ڲ�ͬ�Ĕ�������( ORL��AR��GT) �����^�õ��R�e����.
�����P �I �~: �D���R�e; ���S�����b�e����; �fͬ��ʾ; �÷��ں�
����1 �� ��
�����沿�R�e�����������R�e���g��ռ����Ҫ��λ�ã�ͬ�r���ڌ��H�������沿�R�e���g�V���ؑ����ڽ�ͨ��ȫ�����֧�������ܹ������I���[1��2]. Ȼ�����沿�R�e���g�Դ����T��������: ��ͬ���ա���ͬ�Ƕȡ�׃��������Пo�ړ���. ��ˣ���θ��õ���ȡ�沿�D����������ʾ�D��ɞ��о��ˆT�о��ğ��c.
����Liu ��������˻��ڎ������D���R�e����[3]��ԓ������ȡ�沿�P�I���ٵ�λ����Ϣ�M���R�e�����˵��۾������ӵ�. Gross ����������ڱ���( Appearance-based) ����Ę�R�e����[4]��ԓ�������沿�D����һ�����w�������沿��ȫ����Ϣ�M���沿�R�e. ���ɷַ���( Principal Component Analysis��PCA) �ǻ��ڱ�����沿�R�e����֮һ[5]��PCA Ҳ�Q�� K-L ׃�Q��������Ҫ˼���nj��沿�D�����D�Q��һ�S����.Ȼ����PCA �������܌����沿�D���P�I���ԁGʧ�������㷨���s���^��. ��� Yang ��������˶��S���ɷַ������� ( Two-Dimensional Principal Component Analysis�� 2DPCA) [6]. 2DPCA ��������Ҫ���D�����D�Q��һ�S������ԓ��������Ӌ�㺆����@�����c����Ӌ����r�hС�� PCA ����. ���ڣ�ͨ�^ 2DPCA ���������f��������ȡ�Ć�һ�������܌����ÈD�����^�õ�������. ��ˣ����Č�ͨ�^���S�����b�e����������ȡ������������ڵ� 2. 1 ����Ԕ����B.
�������⣬����������ϡ���ʾ( Sparse Representation) ����[7]�����沿�R�e�dz���Ч. ԓ�������F����Ҫ˼���Ǽ��O�o��һ���yԇ�ӱ������������ȫ�wӖ���ӱ����ԽM�ρ����Ʊ�ʾ���M���@ȡϡ���ʾϵ����Ȼ��Ӌ��o���Ĝyԇ�ӱ��������Ӗ���ӱ�֮�g�Ě����������С��e��ԓ�yԇ�ӱ���e. Wright ��������yԇ�ӱ���������ͬ�Ӗ���ӱ����Ա�ʾ��ϡ���ʾ����Ҳ�Q��ϡ���ʾ���( Sparse Representation based Classification��SRC) [8]. SRC ����ͨ�^ l1 ������õ�ϡ�������^�õ�ϡ���ԣ�Ȼ����ԓ���������^�ߵ�Ӌ����r. ���˽�Q�����@�����}��Zhang ����ͨ�^ l2 ������ϡ��⣬l2 �����^ l1 ������õ�ϡ�������^����ϡ���ԣ��������r���Դ����Ӌ����r���˷����Q��fͬ��ʾ �� � ( Collaborative Representation based Classification�� CRC) [9]. ���Č����� CRC �������������ڵ� 2. 2 ��Ԕ����B.
����Xu ����ͨ���Ե÷��ںϷ������������ںϷ����͛Q�ߌ��ںϷ������ɷN�����M���ں�[10-13]. �������ںϷ����nj�ȫ��������������һ���ӱ��M���R�e��Ȼ����ͬ�������������^��IJӰ����R�e����. �Q�ߌ��ںϷ�������ε�һ�N�ںϷ��������������ں�Ч���Բ��������ɷN�ںϷ���.�÷��ںϷ���[14��15]�nj�ÿ�������ó��ĸ��Ե÷�( Ҳ�Q����x) �M���ں�. ��ˣ����IJ���һ�N�ә�÷��ںϙC�ƌ���g̓�M�D���̓�M�D���ԭʼ�D��[16-18] �քe�� CRC �ϵī@�õ÷ֲ��M���ںϣ����ڵ� 2. 3 ��Ԕ����B. ������C���ķ������R�e���ܣ��քe�� ORL��AR��GT ��ͬ���������M�Ќ��.
�������ĵ���Ҫؕ�I����:
����1) �����״���������S�����b�e��������gɢ����ꇺ��ɢ������M��������ȡ���M���õ��������������g�����������. ��Ч�����ˆ�һ�������ܺܺõر�ʾ�D��Ć��}.
����2) �������������g������������cԭʼ�D���ǻ��a��.
����3) ���IJ����·f�ļә�÷��ںϙC�ƌ�ԭʼ�D��� 2) �������M���ں�.
������������M������: �� 2 ����Ԕ����B���������; �� 3 ����չʾ���������������; �� 4 �����ṩ�ˌ��Y��; �� 5 ���ֽo���˱��ĵĽYՓ.
����2 ����ķ���
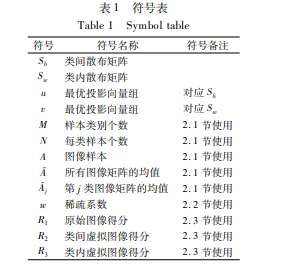
���������漰�Ļ�����̖��� 1 ��ʾ.
����2. 1 ��g̓�M�D����̓�M�D��
��������ͨ�^���S�����b�e����������gɢ����ꇺ��ɢ����ꇣ����ҷքe�M��������ȡ. ���x��gɢ����� Sb ���ɢ����� Sw . �քe�� Sb ������ͶӰ�����M u �� Sw ������ͶӰ�����M v���Ķ��������沿�D��քe�� u �� v ��ͶӰ�õ����Ե��������������w�^������:
�������P֪�R���]����Ę�R�e���PՓ��Ͷ���ڿ����]
������ӱ�e�� M ������ j ӱ��� N ���D��: Aj 1��Aj 2�� …��AjN��ÿ���D����� m × n �ľ��. ���x�ʄt���� J1 ( x) = uT Sb u���� uT Sb u ȡ���r���D���ꇌ������M u ��ͶӰ�@�� ����������e�g��ɢ�̶��. uT Sb u���ȡֵ���}�����D������� Sb ����� g ������ֵ�������������������}.
����2. 2 �fͬ��ʾ���
����ᘌ����沿�R�e��С�ӱ����}��ϡ���ʾ�����ǽ�Q�@�����}��ѷ���֮һ. ϡ���ʾ��������˼����ͨ�^�o���yԇ�ӱ� y ������Ӗ���ӱ����ԽM�ϱ�ʾ���������ϡ��ϵ��������ÿ�Ӗ���ӱ���ϡ��ϵ���ؘ����c���Мyԇ�ӱ��M�з��. ϡ���ʾ�������w�^������:
�������O��� Aj ��ʾ�� j �����Ӗ���ӱ����ӱ�e������ M. ӛ A =[A1��A2��…��AM]��A ��ʾȫ�wӖ���ӱ��M�ɾ��. �o��һ���yԇ�ӱ� y ��������Ӗ���ӱ����ԽM�ϱ�ʾ���� Aw = y
����2. 3 �÷��ں��c�D����
������������ǰ���B����Փ���÷��ںϷ������Ȫ��������������������ó������R�e�Y�������M���ںϣ��÷��ںϷ�������������ںϷ���������ȡ���^���b�e����.
����3 �㷨�IJ��E������չʾ
����3. 1 �㷨���E
���������� 2 ���ֵķ������ƌ����҂��� ORL �������������U�����ķ�������Ҫ�������E.
�������E 1. �� ORL ������֞�Ӗ���ӱ����͜yԇ�ӱ�������: ÿ��e�xȡǰ 2-5 ������Ӗ���ӱ�����������yԇ�ӱ�. ����Ӗ���ӱ����͜yԇ�ӱ������沿�D���С�yһ�O�Þ� 50* 50 ����.
�������E 2. ���ù�ʽ( 1) -��ʽ( 3) ����ԭʼ�沿�D��Ӗ���ӱ�������gɢ����ꇣ�ͨ�^������ȡ��ʽ��ȡ���������������������ù�ʽ( 4) ��Ӗ���ӱ����͜yԇ�ӱ����քe����ȡ����������������ͶӰ���õ�����Ӗ���ӱ�����g̓�M�D��͜yԇ�ӱ�����g̓�M�D��.
�������E3. ���ù�ʽ( 2) ����ʽ( 5) ����ԭʼ�沿�D��Ӗ���ӱ������ɢ����ꇣ�ͨ�^������ȡ��ʽ��ȡ�c֮���������������������ù�ʽ( 6) ��Ӗ���ӱ����͜yԇ�ӱ����քe����ȡ������������ͶӰ���@�Ì���Ӗ���ӱ����̓�M�D��͜yԇ�ӱ����̓�M�D��.
�������E 4. ����ϡ�����w���F��ʽ w = ( AT A + γI) - 1 AT y ��ʽ( 10) �քe�@ȡԭʼ�沿�D���Мyԇ�ӱ� y �ĵ÷֡���g̓�M�D���Мyԇ�ӱ� y �ĵ÷ֺ��̓�M�D���Мyԇ�ӱ� y �ĵ÷֣����� γ ��ʾһ����С�ij�����I ��ʾ���λ���.
�������E 5. �քe�@ȡ����ϵ�� q1��q2 �� q3����ͨ�^��ʽ( 11) �ں�ԭʼ�D��ĵ÷֡���g̓�M�D��ĵ÷ֺ��̓�M�D��ĵ÷�.
�������E 6. ͨ�^��ʽ( 14) ���ںϺ���K�ĵ÷��M���沿�D���R�e.
����3. 2 �㷨����չʾ
���������x�߸�ֱ�^���˽Ȿ��ԭ����ͨ�^�D 1 չʾ�˱����������g̓�M�D����̓�M�D��ʾ��D. ����ͨ�^ 2DLDA ����ȡ�D�����g�������������ͨ�^������ȡ�ķ�ʽ�ؘ���g̓�M�D����̓�M�D����g̓�M�D����̓�M�D���cԭʼ�D���ǻ��a��. �ڈD 1 �У��� 1 ��չʾ��ԭʼ�D�� 2 ��չʾ����g̓�M�D�� 3 ��չʾ���̓�M�D��.
����ͨ�^�D 2 չʾ���xȡ��ͬ�������������������R�e�e�`�ʵ�ֱ�^�D. �ĈD 2 �п��Կ�������������ķ������xȡ��ͬ�������������£��R�e�ʵĿ��wڅ����څ��ƽ���ģ����з�����. ���������������x�� 15 �r�����ķ����沿�R�e�e�`�����.
����ͨ�^�D 3 չʾ�˲�ͬӖ���ӱ������������R�e�e�`��. �ĈD 3 �п��Կ�������������ķ��������^�͵��e�`�R�e�ʣ��S��ÿ�Ӗ���ӱ����������ӣ����沿�R�e�e�`��Խ��Խ��.
����4 ���Y��
���������Mһ���yԇ����������������ܣ��� ORL��AR �� GT �������Ϸքe�OӋ�ˌ��. �҂��OӋ�˅fͬ��ʾ����������ٵ����㷨( Fast Iterative Shrinkage Thresholding Algorithm��FISTA) ��ͬ����( Homotopy Method) �����V�������ճ��ӷ�( Primal Augmented Lagrange Multiplier��PALM ) ���քe�������㷨.
�������²����R�e�e�`�ʁ����^�㷨֮�g���ܵĺÉģ��R�e�e�`��Խ�ͣ��㷨������Խ��. �� 2-�� 4 �У�“���ķ���”��ʾ�� ORL��AR �� GT �沿�������ϵ��R�e���ȣ����w�錢ԭʼ�D����g̓�M�D����̓�M�D��քe���� CRC �M�е÷֣��������й�ʽ( 11) ��ʾ�ļә��ںϙC���M�е÷��ںϣ���������K�÷��M���沿�R�e.“��g̓�M�D��/�̓�M�D��/ԭʼ�D�� + CRC /FISTA /HOMOTOPY /PALM”�քe��ʾ�ڲ�ͬ����������g̓�M�D��/�̓�M�D��/ԭʼ�D���ڷ���㷨�� CRC /FISTA /HOMOTOPY /PALM �ϵ��R�e�Y��; �ı� 2-�� 4 �п��Կ�������������ķ��������沿�D���R�e�����^�͵��R�e�e�`��.
����4. 1 �� ORL �沿�����ϵČ��
������������ ORL ��Ę�������M�Ќ��. ORL ��Ę����������� 40 ���ˣ�ÿ���� 10 ���D�� 400 ����Ę�D��. ÿ����Ę�D����ڲ�ͬ�Ĺ��ա���ͬ�ı���׃������ͬ�ĽǶȗl���«@��. �� ORL ��Ę�������ЈD����������׃��( Ц��Ц�����ۻ��]��) ���沿����. ÿ����Ę�D��ֱ��ʾ��� 50 ���� × 50 ���أ�ÿ����Ę�D��ĸ�ʽ��'. bmp'. �D 4 �@ʾ ORL ��Ę������IJ��ֈD��.
������ 2 չʾ���� ORL ��������R�e�e�`�ʣ�ÿ����ԇ��ǰ 2-5 ���D������Ӗ���ӱ��������D������yԇ�ӱ�. �ı�2�п��Կ��������ķ����� ORL �������Ͼ����^�͵��e�`��.����: ��ÿ�Ӗ���ӱ������� 2-5 �r�����ҷ�����x�� CRC �r�����ķ������R�e�e�`�ʞ� 14. 06% ��12. 14% ��8. 33% �� 8. 00% . Ȼ����ԭʼ�D������ CRC �M�з�r�������R�e�e�`�ʞ� 16. 25% ��14. 64% ��10. 83% ��11. 00% . �ɱ� 2 ��֪������ͬӖ���ӱ������� 2 ׃���� 5 �r����������ķ���Ҳ���īI[18]����( 2DPCA + Original images + CRC) ���īI[17]���� ( FFT + Original images + CRC) ���īI[15]�е�һ���ںϷ���( Gabor + L1LS) Ч��Ҫ��.
����4. 2 �� AR �沿�������ϵČ��
������������ AR ��Ę�������M�Ќ��. AR ��Ę�������а����� 120 ���ˣ�ÿ���� 26 ���D�� 3120 ����Ę�D��. �D���ڲ�ͬ���ա���ͬ�沿���顢��ͬ�ǶȺ��Пo�ړ���( �����R�����) �l���«@��. ÿ����Ę�D��ķֱ��ʾ��� 50 ���� × 40 ���أ�ÿ����Ę�D��ĸ�ʽ����'. tif'. �D 5 �@ʾ AR ��Ę������IJ��ֈD��.
����ÿ����ԇ��ǰ 9-12 ���D������Ӗ���ӱ��������D������yԇ�ӱ�. ����: ������x�� CRC �r����������ķ����e�`�ʞ� 30. 74% ��32. 76% ��23. 11% ��24. 88% . Ȼ����ʹ�� FISTA ��ԭʼ�D���M�з����ÿ�Ӗ���ӱ������� 9-12 �r�������R�e�e�`�ʞ� 44. 95% ��47. 71% ��34. 33% ��35. 89% . �ɱ� 3 ��֪����ÿ��Ӗ���ӱ������� 9 ׃���� 12 �r����������ķ����� AR �������ϵ��R�e�e�`�ʵ���ԭʼ�D��ʹ�� FISTA ���R�e�e�`��.
����4. 3 �� GT �沿�������ϵČ��
������������ GT ��Ę�������M�Ќ��. GT ��Ę�������а����� 50 ���ˣ�ÿ���� 15 ����ɫ�D�� 750 ���D��. �� GT ��Ę�������У�ÿ���˵��沿�������沿���鶼��������ͬ�̶ȵ�׃��. ��ÿ����Ę�D��ĉ��s�� 50 ���� × 50 ���أ�����Ќ��@Щ��ɫ�D���D����ҶȈD��. ÿ����Ę�D��ĸ�ʽ����'. jpg'. �D 6 �@ʾ GT ��Ę������IJ��ֈD��.
������ GT �������У�ÿ����ԇ�ߵ�ǰ 9-11 ���D������Ӗ���ӱ��������D������yԇ�ӱ�. ͨ�^�� 4 �Č��Y����֪����ÿ�Ӗ���ӱ������� 9-11 �r���ҷ�����x�� CRC �r������������沿�R�e�����e�`�ʞ� 28. 67% ��26. 80% ��24. 00% . �īI[17]�������R�e�e�`�ʞ� 31. 67% ��32. 00% ��27. 50% �����īI[18]�������R�e�e�`�ʞ� 32. 67% ��29. 60% ��29. 50% .�ɱ� 4 ��֪����������ķ����c�������䷽����Ⱦ����^�͵��R�e�e�`��.
����5 �Y���Z
������������˶��S�����b�e�����ͅfͬ��ʾ���沿�R�e����. ԓ�����ڲ�ͬ��Ę�������п��ԫ@���^�õ��R�e����. �ڌ��H�����У�ԓ����������Ч�ԺͿ����ԣ�����Ҫ�ք��{�������������ڌ��F. ���ķ������ԫ@ȡ��g̓�M�D����̓�M�D�����ʾԭʼ�D���H�����ˈD���P�I������Ϣ���������沿�R�e�����cԭʼ�D�����һ���Ļ��a�ԣ������ˈD���R�e�e�`��. ͨ�^�����������沿�R�e�Ќ���g̓�M�D���̓�M�D���ԭʼ�D��ķ�Y���M���ںϿ���ȡ���^�õ��R�eЧ��.——Փ�����ߣ��ֿ������� ����
SCISSCIAHCI